Nothing like online currency to get people interested. So, obviously I am a few years too late to this party, but the main concepts of the technology are still relevant.
As most people know by now, the most famous application of Blockchain technology is cryptocurrency, most notably Bitcoin. But what is it? How is it better than just going to the bank and getting money, or using a bank’s online transfer system?
Essentially, anytime a transaction occurs between say, a group of 4 people, a separate “block” of memory is created for each of the 4 friends. Each block has the details of the transaction permanently inscribed on it. Imagine a group of 4 people named A, B, C, and D.
On a side note, there are currently ~400 people named ‘ABCDE’ in the continental US.
Suppose one day they all go for dinner at Olive Garden. After an evening of unlimited breadsticks, C says that he will take care of the bill for now and the others can just send in their share through Bitcoin. The next day, A,B and D all send in their transactions in a group. Everytime one of them sends money to C, a separate block is created detailing who paid whom, how much, and the reserve bitcoins left over for all the members in the group, not just the ones in the transaction. These blocks are then linked together (blockchain, super creative), and each individual is given a copy of all the blocks. This link of all the block is called a ‘public ledger’. Thus, the proof/details of the transaction is available to every single person involved.
This increases the security of the transaction as well, as there are multiple copies of the block with all of the involved persons, meaning that a single person being hacked would not be as effective as hacking someone’s bank account.
Another side note, these transactions are encrypted using different variations of the public-private key encryption that we talked about last time. Bitcoin specifically uses the SHA256 hash-key encryption system. This system allows for secure data storage, and that involved/uninvolved persons cannot meddle with the details of the transfer.
Check out this video by Simply Explained to understand more about Blockchain and how it works. Next time, we’ll look at some more history-based concepts. Until then, good luck.
Alright then, so cryptography. Cryptography is essentially the concept of secret codes, but developed to a certain point. Modern cryptography is heavily based on mathematical theory and computer science, and cryptographic algorithms are designed to be difficult to break by any opponent. Cryptography allows people to protect their information and keep it safe from potential hackers, and is invaluable for the big-tech companies of today.
Cryptography includes techniques such as microdots, merging words with images, and other ways to hide information. Today, cryptography is mainly associated with scrambling “plaintext” (just regular text) into “ciphertext”. This process is known as “encryption”, where in the text is made into secret code that can be then “decrypted” back into plain text after the data is transported to where it needs to be.
Think of cryptography as essentially a cipher, like the coded messages sent by Julius Caesar to his allies. Only a select few people with the right key to decode the cipher will be able to read the text.
I always loved the old Asterix and Obelix books, but I never really got them.
The most common and well-known method of cryptography is “public and private key” encryption done in the RSA (Rivest-Shamir-Adleman) method. This is very common over the internet, where encryption is very much necessary. Public key cryptography uses two different but mathematically similar keys, being the private key and the public key. The public key is, well, public. Anyone can see it and use it, but the private key is to remain just with you.
This public-private encryption can be simplified to a simple exchange. Say your friend wants to send you some old, embarrassing pictures. Now you have a safe that you keep empty and you realize that you can use it to keep the pictures in, so that no nosy family member can take your precious memories. But what if someone takes them while you are bringing the pictures over? You decide you can send the safe to your friend so that they can put in the pictures, and thus bring them over safely. However, you can’t trust your friend with a key to the safes’ padlock, as their siblings are very annoying and could steal it. So, what can you do?
A simple way to do it is for you to send the open, empty safe that anyone can access (the metaphorical public key) to your friend. As the safe is empty, no one will want to take it. Your friend can then put in the pictures and close down the padlock. This way, no one at their house can open it as they only have a safe and not the key. Your friend then sends the safe back, and you can use the key that you have (your metaphorical private key) to open it and secure the pictures.
Personally, I would have just stolen the safe itself.
Either way, the data that you transferred is now secure (in one way), and your embarrassing moments are long forgotten.
If you want to learn more about cryptography, check out this video by MIT OpenCourseWare detailing the RSA method. And if you want to learn about how quantum computers can break the public key encryption method, check out this video here by Frame of Essence. Next week we will look at everyone’s favorite, bitcoin and blockchain. Until then, good luck.
Hello again. Today, let’s take a look at a fundamental part of algorithms – run time. The question that big O notation tries to figure out is ‘How long will it take for something to happen?’ What you’re trying to achieve with big O notation is to get an estimate of how long it will take to accomplish a certain task that the program is trying to do based on how big the data it is handling is. Let’s imagine it this way-
Suppose my friend and I live close to each other.
Yeah the neighborhood sucks, but the rent is pretty nice.
Suppose one day I find a pirated movie online, and I want to send him the file (sure). Both of our internet connections are really, really slow cause it’s cold and somehow that seems to affect the router. Now, if the movie is really long, like upwards of 90 minutes, sending it over the internet is going to be really slow. Both of us have stuff to do later, so we can’t wait that long. How will we both enjoy pirated movies together then? Obviously we can’t watch it separately.
One solution to this is that I could simply get the movie on a USB, and then start walking along the convenient path apparently made only to connect my house to my friend’s house.
Gotta go fast. (For anyone confused, the thing in my hand is the USB)
Our houses are about 15 minutes apart if I walk fast. That way, I can get the movie to him in time, and we can both enjoy watching it at the same time (right after I run back to my own house).
Here, we say that the data transfer of the movie file itself takes ‘O(n)’ runtime. Here, this is just saying that the bigger the movie file is, the longer it takes to transfer, which is obvious. If I was just sending my friend a 5 second clip, then it would be done much quicker than if I was sending him a 2 hour movie.
However, the second trick of me running to his house will take ‘O(1)’ or constant runtime. In this case, it doesn’t matter how big the movie is. It’s on a USB, so even if it was a 50 hour documentary, the time it takes for me to grab the USB and run to my friends house will be the same. We can see that if the data file is big enough, it is almost always faster for me to run to my friend instead of waiting to send the file, as the time it takes is constant (not affected by input size).
Now let’s look at this in terms of computer commands. Let’s say we have a line of code like this:
int x = 5 + (12*18);
int y = 12+90001;
System.out.print(x+y);
We say that this is constant runtime again, as this will always take the same amount of time to do. There is no variable input here, as each step is decided in constant time. The actual runtime comes out to O(1) for each step, or 3*O(1) in total. However, we drop any constant multiple as it doesn’t affect the final result, meaning the actual runtime is O(1).
Now, I have another line of code that says:
for x in range (0,n) { System.out.print(x);}
We can’t say that this is constant anymore. Sure, the printing step takes constant time, but how many times is that step carried out? According to the loop, it is carried out ‘n’ times, so the runtime is n*O(1), or O(n). This means that the bigger that the variable ‘n’ gets, the longer it will take to finish this task. Even if I add to the code, say :
for x in range (0,n) { System.out.print(x);}
int y = 12+90001;
System.out.println(y);
This does not affect the runtime, as the final runtime is still (2*O(1)) + O(n). Here, the 2*O(1) is irrelevant, and when calculating runtime, we look at the biggest value to find the final runtime. So the runtime for that block of code is still O(n).
There’s many other versions of runtime algorithms that take different amounts of time to finish, but let’s look at one final one.
If I have this line of code:
for x in range (0,n) { for y in range (o,n) { System.out.print(x*y); }}
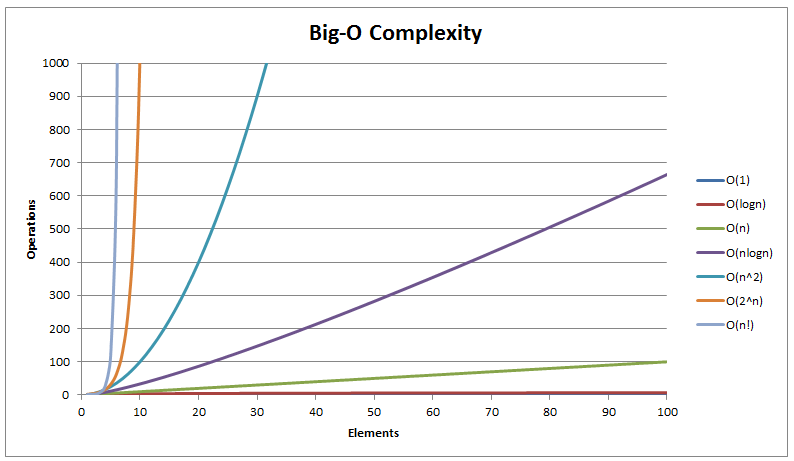
Here, the loop is not only carried out once, but once for an ‘n’ number of times. The runtime here is literally O(n) * O(n), or O(n^2). This is slower than both of the previous steps, meaning that this last one gets really, really slow as the input is larger.
Look at that line grow. Everything above the purple line is dangerously slow.
Take a look at this video by HackerRank to understand more about big O notation. This is a pretty basic overview. There are other cases to consider, like what if you have an ‘if’ statement where one condition takes constant time, and the other takes quadratic time? Here, you would still say the runtime of the algorithm is quadratic, or O(n^2). While doing big O notation, we are always looking for the worst-case runtime of the code. It doesn’t matter how fast it usually is, it’s about how slow it can be. Also, unlike I said earlier, even if for the official runtime, we consider the biggest value in the runtime as the number, the constants and multiples matter in real life. Just make sure you know that big O gives you a worst case scenario.
If you want a best case, look up ‘big omega notation‘, and if you want an average case, look up ‘big theta notation‘. Runtime just helps you get a feel for how long a task will take. Of course, if you work in CS, you’re job is to make sure that the runtime is as fast as possible, so work on improving it piece by piece. On a side note, don’t run with a USB stick in your hand. It looks suspicious. Next week, we’ll look at another concept, maybe sorting. Until then, good luck.
Today, we will be discussing some data structures. Now, what are data structures? Well, basically when you store any kind of object in your room, do you want it to be messy, or stuck in pile of god-knows-whatever objects and impossible to dig out until months later by accident? Or do you want it to (or hope it somehow will be) stored properly, where it is easily locatable? Hopefully, everyone picked the latter. Basically, a data structure is a tool that helps organize any incoming data in whatever order is required for that specific data.
Hopefully this isn’t you. I’m 99% sure this is a crime scene.
First, let’s look at a pretty well known data structure : Arrays. Arrays are a relatively common data structure, familiar to basically anyone with a highschool level understanding of CS. Basically, an array is like a whole group of numbers assigned to a variable. For example, if group of primitive integer variables are defined as :
g = 6
h = 7
y = 9
Instead you can define an array and say
j = {6,7,9}
A specific value in this array is marked with an “index”. Basically, each entry is labelled starting from 0. Here, j[0] would refer to the ‘6’. It gets a little confusing as you would expect j[3] to give ‘9’, but here since you start indices from 0, ‘9’ is actually j[2]. j[3] would be an error (rather an “exception“). To understand an array, just think of a table.
Not the most exciting table, but hey. Courtesy of Desmos.
Basically, if you try to put in j[0], the system would go to the first entry, move down however many values the number in the bracket specified, and return the corresponding entry. Arrays are pretty common, but it is reasonably complicated to remove or add elements to an array. Usually, arrays come in set sizes and stay that way.
Also, keep in mind that arrays can only store on dimensional data (basically just a line). If you need to store data for a whole grid, you need something better.
Presenting, two dimensional arrays!
Very creative name, I know.
Two dimensional arrays work pretty much the same way, except now you need to specify rows and columns, so j[0][3] refers to the value in row 0, column 3. Try not to think of it as an entirely new structure. A two-dimensional array is basically just an array of arrays, if that makes sense. Think of an array, but instead of each element j[n] referring to one specific number, it refers to a whole other array.
Let’s look at some other data structures. A linked list is a data structure that’s like a train. Each value in the list is a “node”, and all the nodes are joined so that each connects to the next one, and the next one and so on. Linked lists are good if you want to add and remove data quickly, you just have to make sure that the pointers going to the removed data are sorted out properly. Linked lists help you, well, link data. Suppose you have a bunch of nodes that were made at different times, so they are spaced out in the computer’s memory. With a linked list, you can join them all together and not have to worry about any data in between. A link list can either be circular, meaning that when you reach the end, it just points back to the start. Imagine a train going in an infinite circle (one of the most useless modes of transport ever created). It can also be a finite linked list, which ends whenever the node is a “null” or zero value. A doubly linked list is one that can go either front or back, so each value points both ahead and behind.
Just skip over the unnecessary one. Just like real life problem solving.
Let’s take a look at stacks, and queues. These are basically just different types of link lists. Queues are all “first-in-first-out”, basically whichever data arrives first is the one pushed out. Think of all the long queues at amusement parks. If you get there early, good on you! But if you don’t, you wait there politely until you can leave.
My god. Is the ride really worth it?
A stack is a last-in-first-out structure (all the people who ever had problems with recursion just shuddered). Imagine a pile of socks. Unfortunately, when you put your socks in a stack, the nice clean ones that you put on top end up getting used first, and the ones at the bottom never see the light of day again. Stacks basically work the same way. Any new data is “pushed” onto the stack, and the same data is the first thing “popped” off.
I have an intense fear of the word “Overflow” now.
Lastly, let us look at trees. A tree is basically a link list with a left and right side. Most people will know what a tree is, just picture all those awful family trees you had to make for school.
Ah yes, nature is so beautiful. Look at them bloom.
Each tree has “parent” and “child” nodes, which basically define if the current node points to anything else or not. The main node , or ‘8’ here, is known as the “root” node, which is odd considering the top of the tree isn’t really the roots, but sure. Trees come in allkinds, and there are even crazier kinds of trees that rotate to balance the number of nodes on each sides (nature in CS is weird).
Well, that’s pretty much it. Data structures provide a convenient way to store data so you don’t just lose it in a heap of random gibberish. Next week, we’ll look at some more in-depth things about, say, algorithms. Until then, good luck.
So. Security. I mean, nobody wants their stuff to be taken or viewed by random people. People don’t seem to like crime, and we have police and locks and other stuff to keep that from happening to our physical things. Similarly, we have cybersecurity for our computers. It is a hard concept to grasp, but computers do not have social skills. They just want a question, and they’ll happily give an answer to anyone who asked. So the same computer that keeps your house safe with a security system will happily let someone else break in without a second thought. So, we have our cybersecurity methods to keep us safe. Cybersecurity tries to follow three specific guidelines –
Secrecy – I mean, who wants private information to be available to strangers? secrecy (or confidentiality) tries to ensure there is no unauthorized access on your cool stuff.
Integrity – Close to the previous one, integrity ensures only authorized people can modify your data or systems. I mean, who wants their Gmail account hacked? I mean also worry about important bank information, but mainly the Gmail thing.
Availability – Authorized people should always have access to their data. What good is a security system that stops you from seeing your own stuff?
Firstly, experts in cybersecurity first try to profile who might try to attack you. Unless you have information threatening the very security of the country (I mean, everybody has that one friend) , chances are that not that many people are trying actively to break into your computer. So, you have a “threat model” made, detailing who might want to break into your laptop. For an average person, the threat model usually might just be ‘annoying sibling’ or ‘disgruntled service employee’, but for more large scale systems, the threat model can be very detailed. Mainly for security, what you are trying to do is figure out who is accessing the system, and how much of the system they should actually have access to.
To figure out if the right person is accessing the system, the computer must be able to “authenticate” the person. Authentication has a few common types, like authentication based on some secret information. Usually, we see this everywhere in the form of passwords. It is a simple system, but there are a few problems with it. If you have, say, a 4-digit pin code to a bank account, and someone wants into that account. They could, perhaps, try asking you, but an easy way for them to break in is using a “brute force attack”. This sounds dark and violent, but really they are just trying every possible combination of 4 numbers in the system, from 0000 to 9999. With a good computer, they can have the correct pin within seconds, so then there must be a way to prevent this. A good method is seen on many iPhones – if the person typing gets three incorrect passwords in a row, the phone locks itself. This is also why, annoyingly, some websites make you have a whole bunch of special characters in you password, from ‘!’ to ‘%’ and all kinds of other requirements. This makes a brute force attack a lot harder. On a side note, a good password for you could also be any 4 random words selected. Seeing as there are over 100,000 words in a typical dictionary, guessing all the possible combinations would be really hard. (https://xkcd.com/936). But maybe, the whole password thing is not for you. Maybe, you somehow keep giving away valuable information to random people. So, you could try another method of security – possession. Think of a locked door. You can only get in if you have a key, but you can’t accidently give it away while talking (Trust me, telling someone “I have a key” doesn’t give it away). So, then the door only opens for you. But this system also has issues – what if someone steals you key and copies it? You might need something else to protect yourself (For some more information, check out this article about PGP encryption). Another method of encryption involves biometrics – fingerprints, eyeballs and other organs. Let’s face it, unless someone cuts off your thumb, you aren’t going to lose it (and if someone does cut off your thumb, your phone security really shouldn’t be the first thing on your mind). However, again, this system has flaws. Against popular opinion, fingerprints aren’t actually unique – it is pretty rare, but someone out there could have the same fingerprint as you. This person can get past your thumbprint scanner with no problem. Also, when it comes to biometrics, there is limited available data. I mean, you could change a password to a combination of literally any other numbers or letters, but you only have 10 fingers. If somebody has all 10 of your prints, you don’t really have much more choice in the matter.
To finish up, let’s look at how the ‘access’ part of the authorization works. How does the system know what it should let you read, and what it should keep private? There are a few general rules as to how it should work:
People shouldn’t “read up”.
People shouldn’t “write down”.
These specific rules are part of the “Bell-LaPadula model” of access control. Check out this site for a few more access control models. Mainly about the Bell-LaPadula model first, what does it mean to read up or down? Well, the first rule is basically saying, “A lower authorization person shouldn’t be able to look at higher authorization things”. Pretty obvious, right? If you have a public file, and a top-secret file, a person reading the public file shouldn’t be able to read the top-secret file, but if you have top-secret access, you can read both files. The second rule is a little less obvious. It says, “A person who can edit the high authorization file shouldn’t be able to edit the lower authorization file”. This seems a little dumb, like if you can write in the top-secret one, why can’t you write in the public one? Mainly, this is so that someone with top-secret access doesn’t accidently leak things into the public document. Naturally, someone with public access can’t write in the top-secret one either.
Well, that’s pretty much it from me. Next week, maybe we’ll look at hacking and some other examples of cyber attacks. Check out this video to learn more about cybersecurity. I’ll see you next week. Until then, good luck.
Considering how last time’s post was about how algorithms “learn”, let’s look at another way in which AI can advance – “Q-learning”. Q-Learning takes a different approach to teaching AI as compared to neural networks. Instead of just multiple rounds of trial and error wherein the AI learns what’s wrong, the AI is instead rewarded for doing good, and punished for doing bad. Try to imagine it like this :
Imagine the AI is a pig, that you want to teach how to stay in one place. In a neural network, first you would obtain a pig.
Pig obtained.
Then, you would wait to see what it did. Ideally, you would bring in more than just one pig.
They are coming.
Now, you would wait. If a pig does something good, you would then let that pig make lots and lots of little baby pigs, and those pigs would do the same. If the pig did something bad, you would get rid of it, and get another.
Good thing, too.
This tries to emulate the ideas of “natural selection”. Good behaved pigs go on to make others, and bad behaved pigs do not. Eventually, all the pigs then know what to do. However, this takes many versions of the pig, and makes a lot of excess bacon. In Q-learning, the pig would instead be given a reward every time it stayed for a long enough time, and punished if it did not. As a result, we get something a lot closer to how human children learn, with the principle of ‘Negative Reinforcement‘.
Good Piggy!
Like our pig friends, the AI would be put on an already created playing field where it wouldn’t know what to do. It would then slowly try to move around. If it did anything bad, it would get a punishment in the form of a low number, and if it did something good, then it would get a reward as a high number. The AI would keep trying out different things, and in the end, the AI would follow all the steps that give the best reward and thus learn to do whatever you want it to.
Q-Learning comes from the “Q-function”, or “quality function”. The AI would use this Q function for every task it does. The Q function is essentially modelled like this:
Q[s(state),a(action)]
Here, the function would consider the current state of the AI. It would then consider the action that the AI is about to take. The function would try to realize the immediate reward it would get for doing the current action, and all the future rewards that the current action would help it get later (the function isn’t “greedy”, it doesn’t try to just look at the immediate reward, it considers the future also). So, while actually working, the process is as follows :
π(s) = argmaxa(Q[s,a])
The ‘π(s)’ part represents the “policy” for state ‘s’, or the action we take in state ‘s’. The equation here tries to test all the possible actions we can take in state ‘s’, and then find the one that gives the maximum reward. A table is then made for all the possible rewards that the AI can get, and then the table is constantly updated as the AI performs more and more actions. The AI then does that over and over until there is a clear picture of what it should do. Finally, the AI can follow the path with the highest reward as listed in the table, and do whatever needs to be done.
For example, take a look at this explanation of the value functions and a simple approach to eating using Q-learning. Also, check out this video by Siraj Raval for a great explanation about how Q-learning works, and this video by Code Bullet again to see a cool car drive around a track with Q-learning. Well, that’s pretty much it for now. Next week, we’ll look at some other stuff with different AI algorithms. Until then, good luck.
With AIs developing as fast as they are, today let’s look at how a well-made AI can make a decision. In the end, the goal of the AI is to take an input, run whatever process it wants on the data and use the data to make a decision. Neural networks try to emulate actual thinking in the computers (Very Terminator-esque, right?) and can be used to play games or even predict illnesses in hospitals. To do this, the network tries to learn about whatever task by taking in as much input as possible. This input (Whatever you want to tally, from age, to SAT scores, to handwriting) becomes a ‘node’ in the network. Try to imagine actual human neurons. Meet Nathaniel.
Now Nathaniel is a special guy. He’s got a lot of friends who like to tell him stuff. Whenever he gets a signal from some of the other neurons, and the signal is strong enough, he passes it on to his own friends.
These are Nathaniel’s friends. They like to keep in touch.
In the brain, the connections in the neurons can be weaker or stronger than others, and the stronger the connection between any two neurons, the stronger the signal is passed between them. Similarly, neural networks “pass on” strong data and values, until they arrive at a result that the user likes.
So let’s visualize a fully developed network. In essence, if you’ve ever tried to make a family tree for yourself, imagine that tree, but on its side. Basically, it is layer after layer of nodes that each connect to the next ‘layer’ and so on, until at the end, the network can have output.
When the network gets any input in the input layer (These are the values that we know), it can use them in value functions, called “Activation Functions”, to try and get a value for the input, which is then passed on through the rest of the layers. The function can be either really simple (Kind of a bad AI if it is though…) or extremely complicated. Each node gets a value, and uses the function to get a number. It then passes the number to each connected node, and on the way, it is multiplied by the ‘weight’ of the connection, or the strength of that particular connection.
So, now that we have a design in mind, we can talk about how the network runs. The network basically works backwards, and tries to figure out what it got wrong. The network checks to see what connection made the output wrong, and then tries to avoid that the next time it runs. As a result, it may take multiple runs for the desired output. There also exist multiple types of neural networks. One kind is the “Feed Forward Neural Network” shown here, passing each value through the rest of the network. However, other types of networks, called “Recurrent Neural Networks” pass the data back into themselves. With Recurrent Networks, you can run programs to make sentences or even write books! (The previous word used matters a lot in a sentence, as it decides what the next word will be).
Well that’s pretty much a general summary of networks. If you want, check out Brandon Rohrer’s video explaining Deep Neural Networks. Also check out Code Bullet on youtube to see flash games made easy with AIs. Neural Networks make it so that the computer can make decisions for itself. As a result, we get swarms of numbers and values that would be too big for humans, which the computer deals with by itself. So let’s see where Neural Networks take us in the future. Until then, good luck.
First, everyone knows we should start with a little history. We all know what computers are (I mean, you’re probably reading this on one right now). But, can we appreciate just how far computers have come since the year they were invented? Well, considering how busy most people are, let’s condense this down. Here’s the history of computers if it happened in one day.
12 : 00 AM : It’s midnight. The year is 1801. In ancient France (well, ancient in this case), Joseph Marie Jacquard creates a special kind of loom. Unlike most other looms, which weave wool normally, this loom is special cause it uses a special kind of punch card to weave in a specific way. This was the origin of punch card computers, which we will get too later.
9 : 53 AM : Nothing much happened between midnight and 9 AM, with the ongoing exciting action happening in the world, from Napoleon to the Louisiana Purchase. However, in 1890, Herman Hollerith devised a system where the census board would use punch cards to track the population. Hollerith went on to establish a company which would eventually become IBM.
2 : 56 PM : If you’ve watched the ‘Imitation Game’, you know what’s happening next. Alan Turing, in order to solve the ‘Halting Problem‘, created the Turing Machine in 1936, a rudimentary computer. His work would eventually lead to the modern macbook I am typing this sentence on.
3 : 16 PM : David Packard and Bill Hewlett create HP (Hewlett and Packard) in a garage in Palo Alto, California.
3 : 29 PM : John Vincent Atanasoff and Clifford Berry create a computer capable of solving 29 equations at a time in 1941. This is also the first time a computer can store information on its memory.
3 : 49 PM : John Mauchly and J. Presper Eckert built the ENIAC (Electronic Numerical Integrator and Calculator) in 1944. The thing is huge, filling a 20 X 40 foot room, and is considered the grandfather of digital computers.
4 : 10 PM : The transistor is created in Bell Laboratories in 1947. It is a device which is capable of blocking the flow of electricity. It can be either on or off, giving the capability for logic gates.
5 : 23 PM : Robert Noyce and his partner, future Nobel Prize laureate Jack Kilby, show off their latest creation : the computer chip in 1958.
6 : 03 PM : The first prototype computer with an actual mouse and user interface is shown by Douglas Engelbart in 1964. Now computers are no longer a specialized tool for scientists, but something that everyone can use.
6 : 47 PM : Developers at Bell Labs create the UNIX OS in 1969. It does not gain popularity in homes, but becomes very useful for large companies.
6 : 54 PM : A new company named “Intel” reveals the first dynamic access memory chip – the Intel 1103 in 1970.
6 : 59 PM : Alan Shugart creates the floppy disk in 1971. Now information can be shared between two computers.
7 : 15 PM : Robert Metcalfe creates the Ethernet to connect multiple devices to each other in 1973.
7 : 29 PM : In 1975, the “Altair 8080 mini computer kit”, a commercial product requires software written in the Altair BASIC language. Two guys named Paul Allen and Bill Gates offer to write the code, and after their success, start a company called “Microsoft”.
7 : 35 PM : Steve Jobs and Steve Wozniak create “Apple Computers” and reveal the Apple 1, the first computer with a single circuit board in 1976.
8 : 08 PM : IBM creates its first personal computer in 1981. It uses MS-DOS from Microsoft and an Intel chip, two floppy disks and a color monitor. It is sold much more widely, and popularizes the term ‘PC’.
8 : 35 PM : Microsoft announces the ‘Windows’ operating system n 1985. At the same time, the first ‘dot-com’ domain name is registered, marking the beginning of the internet.
9 : 09 PM : A researcher at CERN named Tim Berners-Lee develops HTML and begins the World Wide Web in 1990.
9 : 49 PM : Sergey Brin and Larry Page create the Google Search Engine at Stanford University in 1996.
10 : 32 PM : It’s getting pretty late. In 2001, Apple announces the Mac OS X, and Microsoft fights back with the Windows XP. By this time, wireless connection and the word ‘wi-fi’ have become popular. The internet has begun.
10 : 59 PM : A video sharing platform called ‘Youtube’ is founded in 2005. At the same time, Google takes over Android, a Linux based mobile OS. Social media, like the platform ‘Facebook’ announced in 2004 is becoming more and more popular.
11 : 42 PM : By this time, the year is 2012. Various famous technologies like the iPhone, the Wii, the Chromebook and other OSs like Windows 7 have been released.
11 : 56 PM : The first reprogrammable quantum computer is created in 2016.
12 : 00 AM : This blog is written by some guy in San Jose, California in 2019.
Wow. That was a trip. It’s fun to try to comprehend how far computers have come over the last centuries. From weaving wool to simulating the interactions of individual particles, computing has come a long way. Hopefully, we’ll see the same growth over the coming years, from AI to other technologies. Until then, good luck.